Microsoft Cognitive Services konusu ile ilgili bir önceki yazımdan sonra diğer başlıklardan birisi olan Computer Vision API’yı (Görüntü İşleme API’si) inceleyeceğim.
Tekrardan kısaca bahsetmek gerekirse, Cognitive Services Microsoft Azure üzerinde bulunan, son kullanıcıların hiçbir şekilde AI, Machine/Deep Learning gibi konulara girmeden yapay zeka servislerini kullanabildiği Microsoft ürünleridir.
Öncelikle şunu belirteyim; yapay zeka ile donatılmış bu servisleri/ürünleri kullanmanız için gitmeniz gereken tek adres Microsoft değil. Bu konuda Microsoft ile yarış halinde olan hatta Microsoft’tan önce bu işe el atmış şirketler var. Diğer firmaların ürünlerine bakmak isterseniz linkleri inceleyin.
IBM Watson, Microsoft Cognitive Services, Google Cloud Platform, Amazon Web Services
NOT : API’yi kullanabilmemiz için belli sınırlamalar mevcut. Bunlar
- URL veya binary image,
- JPEG, PNG, GIF, BMP formatları,
- 4MB’dan küçük boyut,
- 50×50 boyutundan yüksek
olması lazım.
Görüntü İşleme API’sini incelerken 5 ana başlık altında yapacağız bu işlemi.
- Resim Sınıflandırma ve Tanımlama İşlemi + DEMO
- Metin Tanıma ve Çıkarma + DEMO
- Thumbnail Üretme + DEMO
- Ünlü kişileri ve Mekanları Tanıma
- Gerçek Zamanlı Video Analizi
Resim Sınıflandırma ve Tanımlama İşlemi
İşlemek istediğimiz resimleri inceleyip kullanıcıya çeşitli kategorilerde verilerin sunulduğu bölüm. Bunu yaparken
- İşlenen resmi etiketlerle (tagging) ve açıklamalarla kullanıcıya bildirir. Etiketleme işleminde önceden tanımlanmış 2 binden fazla etiket kullanılıyor,
- İşlenen resmin yetişkinlere yönelik olup olmadığı gibi bilgileri de işaretleyerek (flagging) kullanıcıya bildiriyor,
- Taksonomi (canlı sınıflandırma bilimi) tabanlı kategori tanımı uygulayarak bilgi sunuyor (86-kategori konsept),
- Resim özellikleri (tip, kalite vb.) hakkında bilgiler sunuyor,
- Surat Belirleme (Face Detection) ile surat koordinatlarını, surat hakkında cinsiyet ve yaş bilgilerini sunuyor,
- Renk tanımlama (12 dominant renk)
Örnek

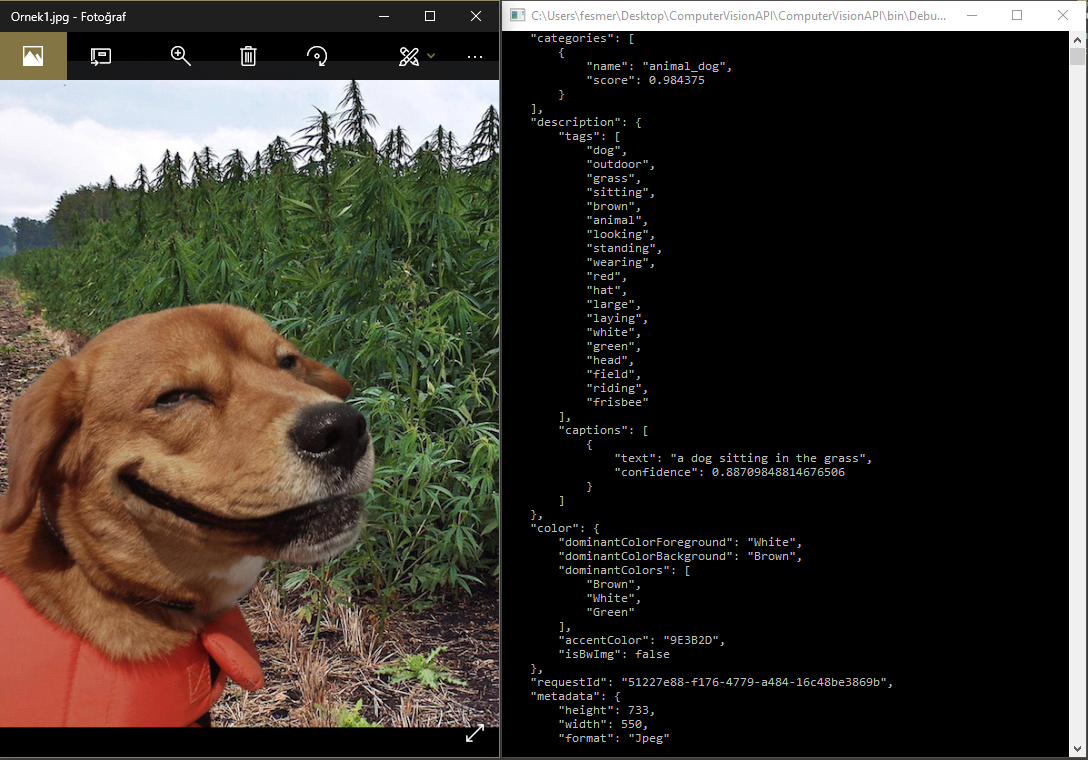
JSON formatında gelen cevapta bahsettiğim gibi tag (etiket) ve description (açıklama) bilgileri bize fotoğraf hakkında AI’ın fotoğrafı doğru yorumlayıp yorumlamadığını gösteriyor. Bir bakalım… Surat tespit edilmiş, gitar çalan kişinin Lemmy olduğu bilinmiş ve 0.7 ile kendisinden emin görünüyor. Açıkhava, çalma, şapka, tutma, erkek gibi ifadeler de var.JSON formatındaki cevap daha da fazla bilgi sunuyor. Yaşı, vücut boyutu vs. Son olarak “woman” ı da eklemiş. Bunu ancak Lemmy’i bilen biri ekleyebilirdi.
Metin Tanıma ve Çıkarma
Bu kısımda API resim içerisinde bulunan yazılı ifadeleri çıkarıp, makinenin anlayabileceği ifadele çevirebiliyor. Diğer bir adıyla Optical Character Recognition (OCR). 25’ten fazla dil desteği mevcut.
Ayrıca, API sadece elektronik ortamda üretilmiş veya belli font ailelerini değil el yazısını da tanıma özelliğine sahip fakat bu özellik sadece İngilizce (şimdilik) dil desteği sunuyor. Türkçe el yazılarını da çeviriyor fakat bazı kısımlarda yanlış yorumlayabiliyor. Bana kalırsa bir insanın yapacağı işi en az süreye indirgeyecek işlem bu.
Örnek

Örnek (El yazısı)

Thumbnail Üretme
API’nin yorumlaması için kullandığımız resmin ana öğesi dışında kalan kısmın (Region of Interest (ROI)) çıkartılarak (crop / kesme) yeni resim oluşturulması. Ana başlıklardan birisinin bu olması kafada soru işareti doğuruyor olabilir fakat farklı kullanım alanları için uygun bir işlem. Klasik thumbnail yöntemleri kullanılacak resimlerin boyutunu küçürmekten ibaret. Bu yöntem iyi değil çünkü tüm resmin küçültülmesi ana öğenin daha da zor görülebilir olmasına sebep olabiliyor. Aşağıdaki örnekte surat hep focus almış.
Örnek

Ünlü kişileri ve Mekanları Tanıma
API’nin sunduğu diğer bir hizmet ise yorumlanacak resimdeki ünlülerin veya önemli mekanların tanınması. 200 bine yakın ünlüyü ve 9 bine yakın önemli yeri tanıyabilir.

Gerçek Zamanlı Video Analizi
Bir videoda mekan ve gerçekleşen eylemleri neredeyse anlık olarak yorumlar. Microsoft Cognitive Services sayfasında son kullanıcının deneyeceği bir alan olmadığı için Microsoft’un bize sunduğu örnekle yetineceğiz.
Örnek
Resim Sınıflandırma ve Tanımlama İşlemi – Demo
Yukarıdaki örneklerin tümünü Microsoft Cognitive Services ekranındaki deneme alanlarında gerçekleştirdim. Henüz tek satır kod yazmadım fakat şimdi her konuyu irdeleyecek şekilde kodumuzu yazmaya başlayalım.
İlk yapmamız gereken, API’yi kullanabilmek için ya Azure platformuna giriş yapmak ya da 30 günlük deneme servisi kullanmak. Yine (diğer makalede olduğu gibi) ikinci yöntemi seçeceğim. API anahtarı ve uç noktasını (endpoint) almak için buraya tıklayıp Microsoft hesabınızla giriş yapın.
https://[lokasyon].api.cognitive.microsoft.com/vision/v1.0/analyze[visualFeatures][details][language]
Endpoint için kullanabileceğiniz parametreler:
- visualFeatures (opsiyonel) : Tags, Description, Faces, ImageType, Color, Adult
- details (opsiyonel) : Celebrities, Landmarks
- language (opsiyonel) : en-İngilizce (default), zh-Çince (simplified)
NOT : Birden fazla parametre kullanımında (aynı kategoride) virgül ile ayırma işlemi yapmalısınız.
NOT : Uçnoktaya analyze ifadesini yazmayı unutmayın. API’nin hangi metodunu invoke edeceğimizi burada belirliyoruz.
Örnekte kullandığım resim ve çıktı aşağıdaki gibidir. Categories, description ve captions kısımları analiz edilen resmin nelere sahip olduğunu bize anlatıyor.
Thumbnail Üretme – Demo
Thumbnail algoritması 4 adımda gerçekleşiyor.
- Dikkat dağıtıcı elementler silinir,
- ROI (Region of Interest / Ana Element) tanımlanır,
- Belirlenen ROI’ye göre resim kesilir,
- En-boy oranı belirlenir.
NOT : Analiz edilecek resmin orjinal en-boy oranı ile Thumbnail sonrası üretilen resmin en-boy oranı arasında farklılık olabilir. Bunun sebebi, son kullanıcı, kesilen resmin farklı boyutlarını farklı ihtiyaçlara göre (cihazda görüntüleme) kullanabilir.
https://[lokasyon].api.cognitive.microsoft.com/vision/v1.0/generatethumbnail[width][height][smartCropping]
Burada invoke edeceğimiz metot Generate Thumbnail.
- width (opsiyonel) : En bilgisi
- height(opsiyonel) :Boy bilgisi
- smartCropping (opsiyonel) : Akıllı kesme işleminin uygulanıp uygulanmayacağı bilgisi (true / false)
En-boy bilgisi yanısıra opsiyonel olarak Smart Cropping seçeneği sunuluyor. Bu seçenek belirtilen oran için en uygun kesimi sağlıyor.
Bir önceki demo’da HttpClient kullandık. Şimdi Microsoft’un kod kullanımını azaltmak adına ürettiği Nuget paketi ile yapalım. İndireceğimiz paketin ismi : Microsoft.ProjectOxford.Vision
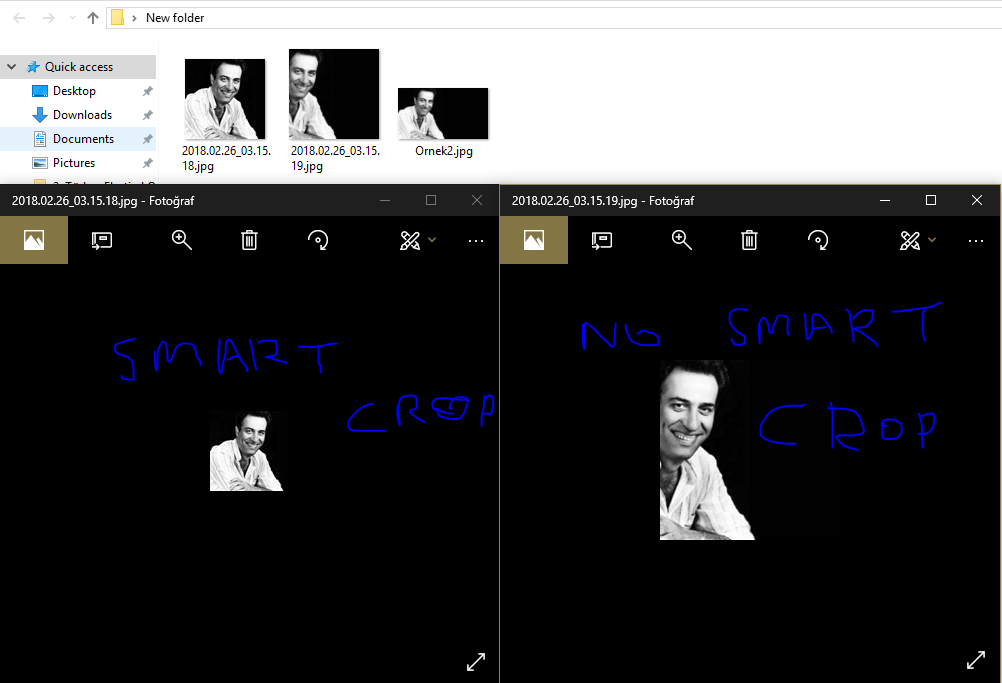
Yukarıdaki kodun ürettiği thumbnail sonuçları yukarıdaki gibi. Soldaki resimde smart crop işlemi yapılıyor, sağdakinde yapılmıyor. Sağdaki resim soldaki resime göre daha başarılı bir kesme işlemi görmüş (Küçük olması boyuttan 80×80). Sağdaki resimde ROI yok.
Metin Tanıma ve Çıkarma – Demo
Resimde Metin Tanıma
Metin Tanıma ve Çıkarma konusunu kısaca anlatırken Optical Character Recognition (OCR)’dan bahsetmiştim. OCR, resim üzerinde bulunan karakterlerin -ki bunlar aslında birer piksel- text/yazıya dönüştürülmesi. Ayrıca OCR ile resimde kullanılan dilin tespiti (+25 dil desteği) de mümkün.
Şimdi biraz API endpoint’i inceleyelim.
https://[lokasyon].api.cognitive.microsoft.com/vision/v1.0/ocr[language][detectOrientation]
- language (opsiyonel) : Dil bilgisi. “Unk” (default) ifadesi auto-detect (otomatik tespit) anlamına geliyor
- detectOrietation (opsiyonel) : true ise OCR servisi resim rotasyonuna tespit/düzeltme işlemi uygular
OCR’ı kullanabilmek için bazı limitler var. Bunlar:
- Resmin 40×40 boyutundan büyük 3200×3200 boyutundan küçük olmalı,
- 10 megapikselsden daha büyük olmamalı,
- JPEG, PNG, GIF ve BMP destekli,
- Dosya boyutu 4 megabyte’tan büyük olmamalı.
Tabi bunlar teknolojik kısıtlamalar. Bunların dışında bulanık, el yazısı, anormal font stilleri, kompleks arka plan veya altı/üstü çizili olması durumunda da API doğru çalışmayabilir.
Demo öncesinde Nuget paketi indirmeyi unutmayın! İndireceğimiz paketin ismi :Microsoft.ProjectOxford.Vision
Yüklenen resim ve çıktısı da aşağıdaki gibidir.

Resimde El Yazısı Metni Tanıma (Preview / Ön izleme)
El yazısı tanıma işlemi OCR’dan pek farklı değil. Analiz edilecek resimdeki pikselleri okuyup belirli kalıplara göre el yazısını yorumluyor. Resimden metin çıkara işleminde bulunan limitler burada da mevcut. Bunlar:
- Analiz edilecek resmin formatı JPEG, PNG veya BMP olmalı,
- Dosya boyutu 4 MB’dan küçük olmalı,
- Resim boyutu en az 40×40 veya en çok 3200×3200 olmalı
GET (Sonuç)
https://[lokasyon].api.cognitive.microsoft.com/vision/v1.0/textOperations/[operationId]
- operationId (zorunlu) : Analiz sonucunun Id’si
POST
https://[lokasyon].api.cognitive.microsoft.com/vision/v1.0/recognizeText/[handwriting]
- handwriting (opsiyonel) : True veya değer verilmezse el yazısı kabul edilir.
NOT : Analiz edilecek el yazısındaki ifadenin uzunluğuna göre süreç uzayabiliyor. Yani direkt olarak sonucu alamadığımız anlar olabilir.
Çıktısı da aşağıdaki gibi. Gördüğünüz gibi bir kelimeyi yanlış analiz etmiş fakat dediğimiz gibi bu servis henüz ön izleme.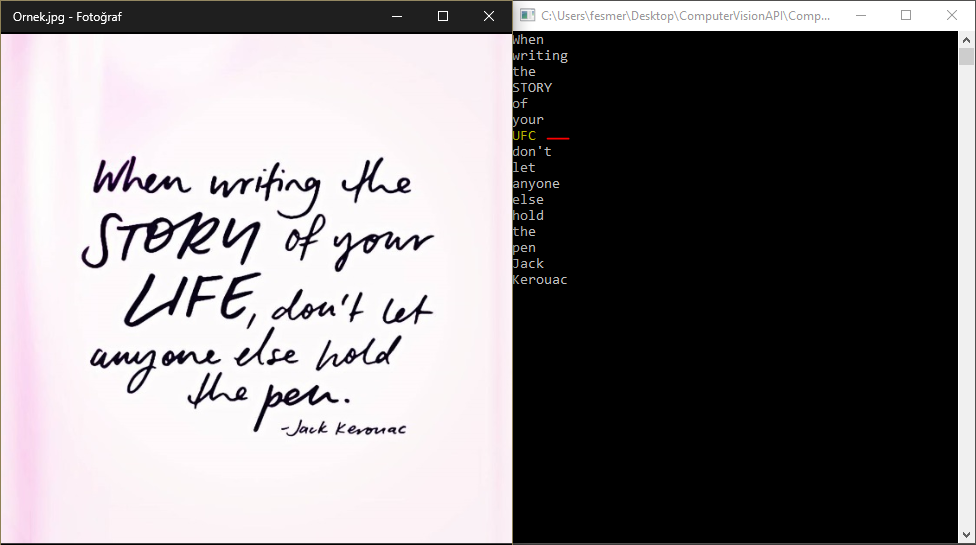
Bu konu ile ilgili söyleceklerim bu kadar. Bu konunun henüz emekleme aşamasında olduğunu ve ileride daha da doğru analizlerle karşımıza çıkacağını unutmayın.